Personalized AI via the Contextual Knowledge Network
Feb 5, 2025

Abstract
The rapid advancement of AI has transformed daily life, with tools like ChatGPT making sophisticated capabilities widely accessible for communication, decision-making, and problem-solving. However, current AI systems lack true personalization, which requires deep integration with users’ personal contextual data. Two major challenges impede progress: first, users typically don’t own or control their data, which remains siloed within various service-providing platforms. Second, building data pipelines for context-based personalization from scratch is resource-intensive, especially when contextual data is scattered across platforms. IsomorphIQ AI solves these challenges through its innovative Contextual Knowledge Stack, which provides a systematic framework for collecting, storing, and managing user-owned contextual data. The system deploys personal AI agents on edge devices to securely gather data from various user-specific sources. This data undergoes privacy-preserving processing before being transmitted to the IsomorphIQ Network, where it’s stored as embedded vectors and knowledge graphs within the Personalized Knowledge Layer. During query processing, the personal AI agent enriches user requests with relevant contextual information from the IsomorphIQ Network, enabling external AI applications to deliver truly personalized responses. By eliminating the need for individual applications to create their own data pipelines, this approach significantly accelerates the adoption of personalized AI applications.
Introduction
The artificial intelligence revolution has fundamentally transformed how we interact with technology, particularly through the emergence of sophisticated language models and AI assistants. While AI has seen remarkable infrastructure advances through more powerful models, improved hardware, and sophisticated training techniques, the progress on applications presents a more complex picture. Despite significant achievements in areas like content generation, code assistance, and creative tools that have revolutionized various industries, these applications predominantly manifest as generic, one-size-fits- all solutions rather than deeply personalized experiences. The gap between infrastructure capabilities and truly adaptive, user-centric applications is particularly evident in the current generation of large language models - while impressively capable, they still cannot deeply understand individual work contexts, learn from ongoing interactions, or maintain meaningful continuity across conversations.
This limitation in personalization stems from two fundamental challenges: first, users typically lack ownership and control over their data, which remains siloed within various service-providing platforms. Second, building and maintaining data pipelines for context-based personalization from scratch is prohibitively resource-intensive, especially given that personal data is fragmented across diverse sources and modalities (emails, documents, calendar events, application usage patterns). Additional technical challenges compound these issues, including the need for sophisticated privacy-preserving processing of sensitive personal information, the complexity of efficiently fine-tuning models for individual users at scale, and the challenge of transforming diverse data types into unified, AI-ready representations that can effectively augment AI interactions with personalized context.
The challenge of implementing effective personalization is not new. Even in the Web 2.0 era, companies invested enormous resources in building sophisticated data pipelines for personalization. Netflix serves as a great example. In 2006, Netflix launched its famous $1 million prize competition to improve its recommendation algorithm. Netflix has spent years building and improving a complex data pipeline that could handle real-time video streaming data, user interactions, and viewing patterns across multiple devices - an effort that is likely to have cost hundreds of millions of dollars.
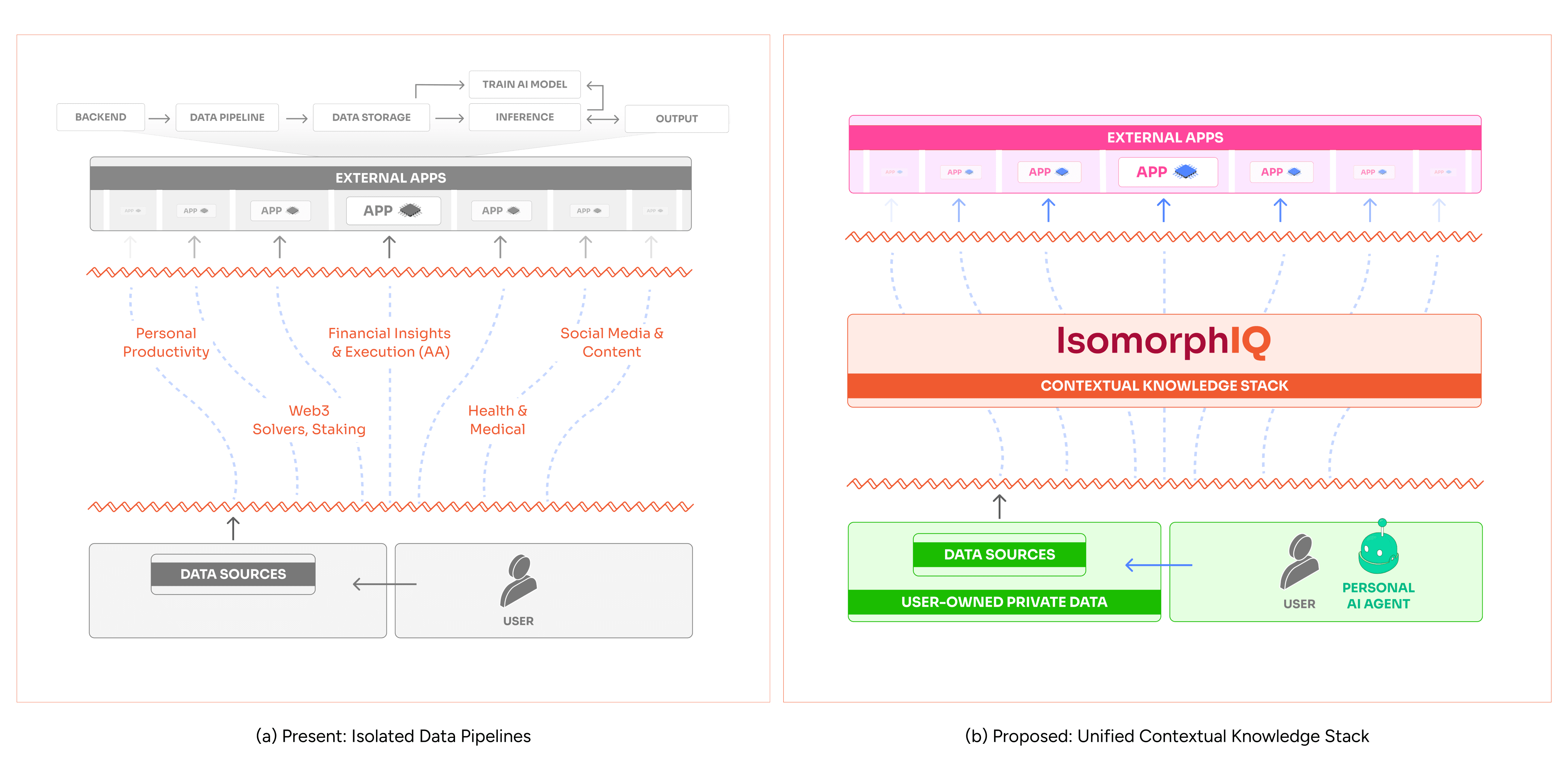
Figure 1: Data Pipelines - Present vs. Proposed
In today’s AI landscape, the personalization challenge has become even more complex. While companies like Netflix could focus on a single type of content (video) and a specific set of user interactions, modern AI applications must process and understand a much broader range of data types and user contexts. This includes not only email communications, calendar events, document content, and application usage patterns but also several other digital footprints that could provide valuable context for personalization.
Unlike Netflix’s focused, single-domain approach, building similar personalization pipelines for modern AI applications would be unsustainable. Each application would need to process multiple data types, handle cross-platform interactions, and maintain privacy compliance - effectively requiring every company to rebuild Netflix’s infrastructure at a larger scale and across more complex data types. This makes the traditional approach of building dedicated personalization infrastructure economically and technically infeasible.
The IsomorphIQ Network addresses this fundamental challenge by providing a unified contextual knowledge stack that securely stores and organizes user-owned contextual data, creating the foundation for truly personalized AI interactions. This shared infrastructure model dramatically reduces both initial development costs and ongoing maintenance overhead for companies. Instead of requiring each application to build and maintain its own data pipeline - a task that would be prohibitively expensive for most companies - our network serves as a universal personal data layer that can be leveraged by any AI application. We enable this through a personal AI agent, deployed on edge devices, such as smartphones. The personal AI agent securely collects data from various user-specific data sources. We then perform on-device, privacy-preserving data processing before transmitting the data to the Personalized Knowledge Layer on the IsomorphIQ Network. Here, the data is further transformed into suitable representations, such as embedded vectors and knowledge graphs, and stored on the network. Whenever the personal AI agent receives a query from the user, it adds contextual information to the query through interaction with the IsomorphIQ Network. This context-augmented query is provided to external AI applications, which can then service the personalized query.
Our approach is built on three key principles:
Ownership and privacy guarantees of user data: Ensuring users maintain control over their personal data through edge processing and privacy-preserving techniques, addressing growing privacy concerns in AI applications.
Standardized data processing and storage for various contextual data types: Providing a unified framework that handles the complexity of processing diverse data sources, from emails to application usage patterns, making it accessible for all applications.
Seamless integration with external AI applications through a personal AI agent:
Enabling any AI application to leverage personalized context without building their own infrastructure, significantly reducing technical barriers to entry.
This paper details the architecture of the IsomorphIQ Network, examining how it processes, stores, and utilizes personal data to enable truly personalized AI experiences. We begin with a technical overview of our system architecture in Section 2 and in Section 3 discuss the future implications and applications of our technology, along with a roadmap.
Technical Architecture
In this section, we provide an overview of the IsomorphIQ system architecture. Each component is described below.
2.1 Personal AI Agent
The Personal AI Agent serves as a gateway between users and the IsomorphIQ network, bridging their interactions with external AI applications. While users experience it primarily as an intelligent interface for asking questions, giving instructions, and receiving responses, the agent’s role extends far beyond this user-facing functionality. From a network architecture perspective, the agent performs three critical functions:
User Interface Management: The agent acts as a unified communication layer between users and external AI applications. It interprets user queries, orchestrates appropriate responses, and delivers services seamlessly.
Privacy-Preserving Data Processing: Operating directly on the user’s device, the agent securely collects and processes contextual data from authorized sources. This local-first approach ensures user privacy while preparing anonymized data for transmission to the IsomorphIQ network.
Context-Aware Query Enhancement: The agent enriches user queries by incorporating relevant contextual data retrieved from the IsomorphIQ network. These enhanced queries are then routed to the network’s auction layer, which algorithmically selects the most suitable external AI applications to fulfill the request.
The personal AI agent is equipped with a Small Language Model (SLM) that can seamlessly work on devices such as smartphones. These models are designed to be lightweight and efficient, enabling real-time processing with minimal computational resources. Despite their smaller size, SLMs leverage advanced techniques like knowledge distillation and fine-tuning to retain the essential capabilities of larger models. This allows them to perform tasks like language understanding, context-aware responses, and personalized recommendations directly on-device, ensuring privacy, low latency, and functionality even in offline or resource-constrained environments.
2.2 Data Sources
To truly realize the transformative potential of AI-driven personalization, systems must be able to leverage cross-application data and contextual insights holistically. Traditional personalization systems operate in isolated silos, constrained by platform boundaries and narrowly focused data streams that serve only specific and limited use cases. This fragmentation significantly limits their effectiveness.
However, accessing comprehensive user context raises serious privacy and security concerns. A fundamental barrier is that users rarely own or control their personal data, which typically remains locked within proprietary platforms and services. This lack of data ownership, combined with the siloed nature of data across platforms, severely hampers the development of truly personalized AI experiences.

Figure 2: IsomorphIQ Architecture
Our system addresses these challenges through a user-centric data governance model where individuals retain complete ownership and control over their contextual data. Only after explicit user authorization does the system begin collecting approved data. This information undergoes privacy- preserving transformations directly on the user’s device before being securely transmitted to the IsomorphIQ network.
Privacy-Preserving Data Management
To address the concerns about privacy, the IsomorphIQ system employs advanced scrubbing, anonymization, and cryptographic techniques to ensure data integrity and security. Data scrubbing removes unnecessary or sensitive identifiers from user information before processing, creating a clean, standardized dataset. Anonymization techniques further enhance privacy by de-linking user-specific identifiers from the data while retaining the core contextual insights. These processes occur on-device, ensuring that raw data never leaves the user’s control.
Additionally, the system leverages cryptographic methods such as zero-knowledge proofs (ZKPs) to validate data without exposing it. ZKPs allow the network to verify the authenticity of user information without revealing its content, enabling user privacy while securely granting external applications access to knowledge representations derived from it. These measures uphold robust ownership guarantees, empowering users with complete control over how their data is utilized.
Ownership and User Empowerment
A core tenet of the IsomorphIQ framework is user ownership and control. Unlike traditional systems that rely on centralized data repositories, our network decentralizes data governance by keeping all sensitive processing local to user devices. Users authorize data sharing through explicit permissions, ensuring that their privacy preferences are respected. Cryptographic key management further reinforces this model, allowing individuals to revoke access to their data at any time. This combination of scrubbing, anonymization, and cryptographic guarantees creates a secure and transparent environment where users are the ultimate custodians of their data.
The foundation of secure, user-centric data management established in the previous sections integrates seamlessly into the IsomorphIQ Network, enabling robust personalization and scalability.
2.3 The IsomorphIQ Network
The IsomorphIQ network forms the core infrastructure of our system, managing both the user’s context and the orchestration of AI services. This network stores user contextual data in optimized representational formats that enable efficient retrieval and processing. When a user initiates a query through their Personal AI Agent, the network facilitates a two-step process: First, it provides relevant contextual data that the agent uses to enrich the original query with personalized insights. Then, this enhanced query returns to the network, where real-time algorithmic auctioning mechanisms determine which external AI applications are best suited to fulfill the user’s specific request.
Architecturally, the network consists of two specialized layers: the Personalized Knowledge Layer and the Auction Layer. These distinct but interconnected components work together to deliver personalized AI services while maintaining system efficiency, scalability, and response time optimization.
Personalized Knowledge Layer The Personalized Knowledge Layer manages and structures user contextual data through advanced representational formats optimized for AI processing. This layer employs multiple complementary data structures, including high-dimensional vector embeddings and semantic knowledge graphs, designed to interface seamlessly with state-of-the-art AI models and algorithms. These sophisticated data representations enable efficient retrieval, processing, and integration of user context across diverse AI applications.
Built upon this foundation, the layer employs a sophisticated decentralized architecture that fundamentally reimagines how AI systems process and manage contextual data. By distributing computational workloads across a network of nodes, the system achieves unprecedented scalability that grows organically with its user base. Unlike traditional centralized architectures that concentrate resources in a single location, our decentralized approach allows each node to process and store a portion of the contextual data, preventing bottlenecks and ensuring robust performance as demand increases.
The architecture’s strength lies in its local-first computation model. Rather than routing all data through central servers, computations occur close to where the data originates. This proximity significantly reduces latency and bandwidth requirements, as only essential information needs to be transmitted across the network. As new nodes join the network, they not only add storage capacity but also contribute additional computational power, creating an infrastructure that scales naturally and maintains high performance even as user demand grows.
Beyond performance benefits, this decentralized design introduces inherent resilience against system failures. The distribution of processing tasks across multiple nodes eliminates single points of failure that plague centralized systems. Our implementation uses advanced cryptographic protocols to ensure seamless coordination between nodes while maintaining data integrity. This careful balance of distributed processing and secure synchronization creates a robust foundation that can reliably handle usage spikes while preserving the system’s efficiency and responsiveness.
Auction Layer The Auction Layer receives user queries that have been enhanced with personalized contextual data and orchestrates a sophisticated selection process among potential AI service providers. Since multiple external AI applications may be capable of servicing any given query, this layer implements a dynamic auction mechanism that evaluates each application’s capabilities, perfor- mance metrics, and specialization to determine the optimal service provider. The selection process considers multiple factors including query complexity, application expertise, historical performance, and computational efficiency to ensure the highest quality response for each user request.
The IsomorphIQ system implements flexible orchestration strategies to execute these auctions efficiently across different operational contexts. At its core, the auction mechanism can operate through smart contracts deployed on high-performance blockchain networks, enabling transparent, secure, and automated bid management. This blockchain integration not only ensures tamper-proof auction execution but also enables sophisticated economic models that incentivize service quality and fair pricing. The system can dynamically switch between on-chain and off-chain execution modes based on specific requirements - utilizing blockchain for high-stakes decisions requiring maximum transparency, while leveraging efficient off-chain computation with cryptographic verification for time-sensitive operations. This hybrid approach optimizes for both trust and performance, allowing the Auction Layer to scale efficiently while maintaining the integrity of its selection process.
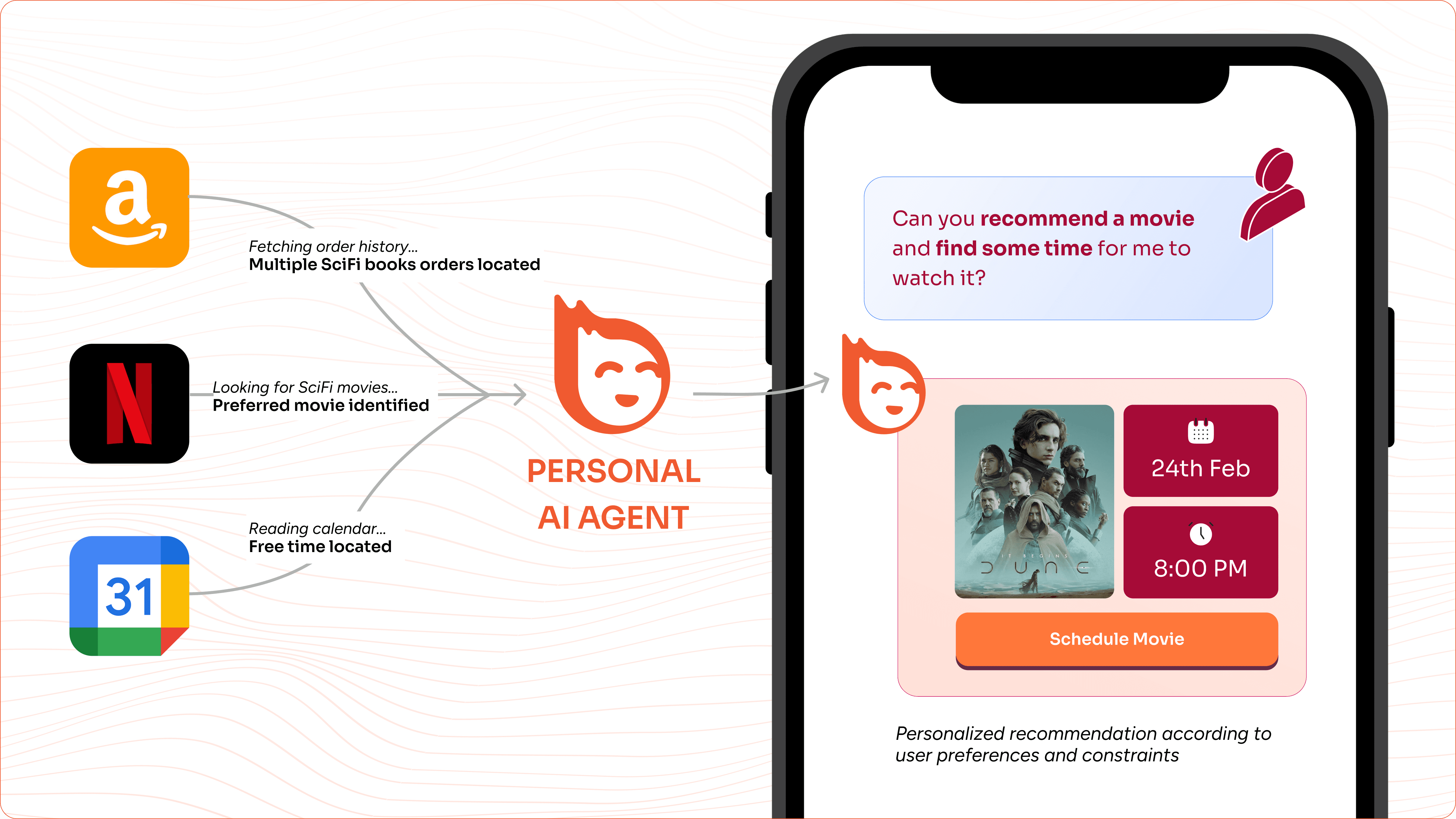
Figure 3: User-Agent Interaction
2.4 External AI Applications
External applications represent a diverse ecosystem of digital services that interface with the IsomorphIQ network to fulfill user requests, ranging from specialized AI tools to e-commerce platforms and entertainment services. Each application brings unique capabilities and domain expertise - from language processing and content generation tools to online shopping platforms and streaming services offering personalized product recommendations and media content. Rather than developing all these capabilities internally, the IsomorphIQ network leverages this distributed network of services through its auction mechanism, selecting the most suitable application for each enriched user query. This symbiotic arrangement benefits both parties: the network gains access to specialized services, while external applications can provide personalized experiences without building and maintaining their own complex data pipelines.
External apps receive contextually enhanced queries through standardized interfaces, process them using their specialized capabilities, and return results - whether that’s an AI-generated response, product recommendations, or media suggestions - that are ultimately delivered to users through their Personal AI Agents. This architecture enables scalability, ensures access to best-in-class digital services, and creates a dynamic, interconnected ecosystem that enriches user experience
An Example: Let’s walk through a practical example of how the IsomorphIQ system enhances the user experience through contextual personalization. Consider a user interacting with their Personal AI Agent on a smartphone. After granting necessary permissions, the agent can access data from various sources including their calendar, email, e-commerce activity, and browsing history. This data is processed on-device and securely transmitted to the IsomorphIQ network, where it’s transformed into sophisticated representations like vector embeddings and knowledge graphs. Suppose that the user asks the agent to suggest relevant tech skills they could acquire, and the system springs into action. The agent retrieves pertinent contextual information from the network: email conversations revealing professional interests, browser history indicating technology trends they’ve researched, books purchased that highlight learning patterns, and calendar data showing available time slots. This rich context enables the agent to refine the original query with personalized parameters. The enhanced query might evolve from a simple “suggest tech skills” to a precise request: “Recommend Machine Learning courses focusing on system design, requiring 6-8 hours weekly commitment, aligned with the user’s demonstrated interest in distributed systems.” This enriched query is then processed by the auction layer, which solicits responses from relevant learning platforms like Coursera and Udemy. The final course recommendation is selected through an intelligent auction process, potentially incorporating user preferences, and delivered as a personalized learning pathway. See Figure 3 illustrating another example.
Future Roadmap and Conclusion
The IsomorphIQ network represents a fundamental shift in AI development, moving from centralized control to individual agency through its sophisticated infrastructure. At its core, the network orchestrates a complex interplay between user context, AI services, and external applications through the Personalized Knowledge Layer and Auction Layer, engineered with a firm focus on data security, scalability, and real-time processing. This technical foundation enables a progressive three-phase deployment strategy that showcases the network’s potential to revolutionize AI-driven personalization solutions. In Phase 1, the platform enables sophisticated Web3 personalization, allowing digital wallets and dApps to deliver highly tailored experiences based on user-owned financial and behavioral data. Phase 2 expands into multi-contextual applications, creating seamless integrations across different aspects of users’ lives, from entertainment recommendations to travel planning. The final phase introduces enterprise-level personal AI agents, capable of transforming organizational workflows through intelligent automation and strategic insights.
What sets IsomorphIQ apart is its bottom-up approach to AI development, where intelligence
emerges from and evolves with its users, both as individuals and as communities. The network’s innovative architecture can maintain and process contextual data not only for individuals but also for diverse communities - from sports team fanbases to professional networks to interest groups. This multi-layered approach enables AI systems that understand and adapt to both individual preferences and community-specific patterns, creating richer, more nuanced personalization at both scales. Rather than having AI behavior determined by centralized training data and organizational decisions, each user and community becomes a stakeholder in their AI’s development through daily interactions. The network’s advanced recommendation algorithms leverage rich contextual data to understand complex patterns and anticipate needs at both individual and community levels, all the while maintaining robust privacy protections and system efficiency. This architecture represents more than just technical innovation - it embodies a new paradigm of “community control” in AI development. Users and communities don’t simply provide input; they actively participate in shaping their AI’s capabilities and responses through their data and interactions. This granular level of influence ensures that AI systems truly reflect both individual needs and community values, creating an interconnected, intelligent, and adaptive ecosystem that democratizes access to personalized AI capabilities.
As we look to the future, IsomorphIQ AI is poised to address the most pressing challenges of the AI era. By combining robust technical architecture with user-centric design and phased deployment, we are not just building another AI platform - we’re laying the foundation for a more democratic and personalized AI future where technology truly serves both individuals and the diverse communities they belong to, fostering a richer, more collaborative approach to AI development and deployment.